SQL Data Loading at 8TB per Hour, 20 Million Rows per Second with Silk on Azure
Relational databases, like Oracle and Microsoft SQL Server, can perform very fast in on-prem data centers. But as we have explored in previous blog posts, these databases struggle to achieve the same levels of performance (throughput, I/O) on public cloud infrastructure. A lack of parity in performance between on-prem and the cloud has kept mission-critical databases stuck on-prem for longer than they need to be.
This blog post spotlights the work of Henk van der Valk, Founder of FullData B.V. and SQL expert. He holds a world record for SQL database performance on-prem and recently broke that record on the Azure cloud.
This breakthrough is important because SQL databases take a performance hit on the cloud, when in fact, using the Silk Platform, they can perform even faster than on-prem!
Back in 2007, Henk set a ETL world record by loading 1.18 TB of SQL Server data within 30 minutes (29 minutes, 54 seconds) on-prem. That’s roughly 2 terabytes per hour and close to 8.5 billion rows of data within 30 minutes. Henk’s presentation slides from the 2021 Data Ceili conference contain the specifics for those wanting to look under the hood.
Fast forward to today: Henk was working with a customer to move all their databases and applications to Azure. A couple of databases stood out because they had high demands for throughput and low latency. The customer challenged Henk to beat the on-prem numbers with Azure. And that’s exactly what Henk did! He tested all the “flavors” of Azure, the premium SSDs and ultra-disks. To beat the record, he would need to load data at twice the speed available on cloud native alone.
To increase performance, Henk introduced the Silk Platform on Azure. Silk provides a data layer that sits between databases and cloud infrastructure. Its architecture connects via the iSCSI layer and enables up to 10x performance. To test the performance of Silk on Azure, Henk used an ETL process, or “Extract, Transform and Load”, where the data is “extracted” from Microsoft SQL Server, “transformed” into the destination format for the Azure SQL database, and “loaded” into the Azure SQL database. He explained the approach in a Microsoft Data Exposed podcast in September.
The results were staggering!
Using Silk on Azure, Henk was able to achieve:
- 20 million rows loaded per second (70+ billion rows in less then an hour)
- 8 TB of data loaded from flatfiles in less than an hour
- 13 seconds to scan a 73 GB data table (on average 5.5 Gigabyte/second)
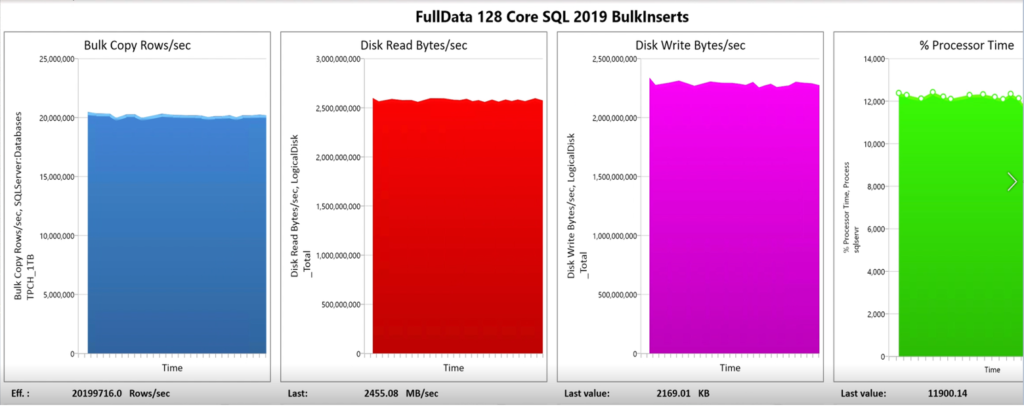 Figure 1: impression of data loading at sustained throughput rates: 8 Terabyte of data loaded within 1 hour: reading 2.5 Gigabyte per second and writing 2.2 Gigabyte per second.
Figure 1: impression of data loading at sustained throughput rates: 8 Terabyte of data loaded within 1 hour: reading 2.5 Gigabyte per second and writing 2.2 Gigabyte per second.
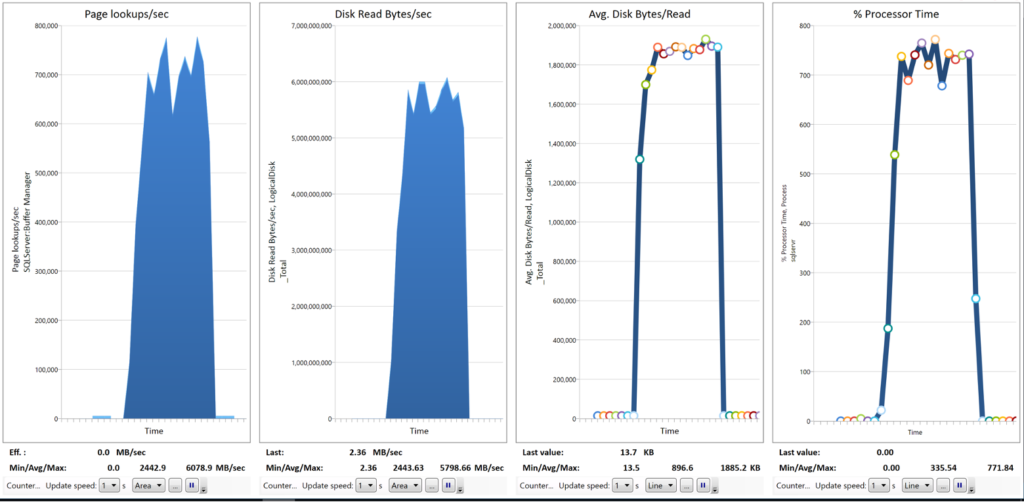 Figure 2: Impression of table scan speed: a full table scan reading 75 Gigabyte of data completely from disk into memory takes 20 seconds. Sustained 5.5 Gigabytes per second is read.
Figure 2: Impression of table scan speed: a full table scan reading 75 Gigabyte of data completely from disk into memory takes 20 seconds. Sustained 5.5 Gigabytes per second is read.
That level of performance is unheard of in the cloud. With Silk, the most demanding SQL workloads can be safely migrated to the cloud with similar or better performance while also benefitting from cloud scale and capacity on demand. This translates to a constant and better customer experience with faster transactions, analysis, and reporting.
Learn how to use Silk to get high performance for your most demanding workloads in Azure.



