Traditional copy data management approaches often rely on cumbersome and storage-intensive methods — such as full data replication — to create multiple copies of data for various purposes like machine learning, AI agents, backups, testing, development, and analytics. However, these conventional methods can lead to significant storage overhead, increased costs, and complexity in managing multiple data copies.
Silk offers a more efficient alternative with its snapshots, views, and clones, designed to manage storage without unnecessary overhead. By using these features, organizations can reduce storage costs and improve data management efficiency. To fully appreciate the benefits of Silk’s approach, let’s explore how its snapshots and views interact with data storage through a few illustrative scenarios.
What’s the Difference Between Snapshots, Views, Clones, and Deduplication?
First, it’s essential to distinguish between snapshots and deduplication. In Silk software, snapshots don’t deduplicate data in the conventional sense. Unlike deduplication, which involves hashing calculations and can introduce overhead, Silk snapshots simply copy pointers to existing data blocks. This subtle difference significantly impacts how data storage efficiency is managed.
What’s a Snapshot?
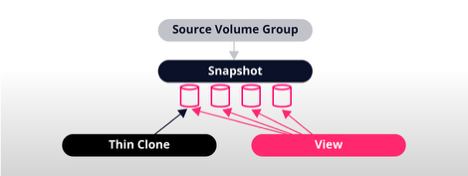
A snapshot is an instantaneous, zero-footprint, point-in-time copy of a volume group. These snapshots are created using a pointer-based “redirect-on-write” mechanism, meaning they initially consume no additional storage space and only require storage as changes are made.
Key Features of Snapshots:
- Instantaneous creation: Snapshots can be created in seconds without impacting performance.
- Zero-footprint: They don’t consume additional storage until modifications occur.
- Immutable: Data captured by a snapshot can’t be changed, thus providing an optional quick restore point.
- Efficient resource usage: Multiple snapshots can be created and used concurrently without significant performance degradation or storage overhead.
What’s a View?
A view is a read/writeable copy of snapshot. A view can be mounted, providing access to the data captured by the snapshot. Changes made to the view won’t impact the underlying snapshot or the source volume group.
Key Features of Views:
- Derived from snapshots: Views are created from an existing snapshot. Multiple views can be created from a single snapshot.
- Access to point-in-time data: They allow users to interact with data as it existed at the snapshot creation time.
- Flexible usage: Views can be used for various purposes, including testing, analytics.
- Minimal overhead: Like snapshots, views are efficient in terms of performance and storage, as they rely on the underlying snapshot data.
What’s a Clone?
Like views, clones are read/writeable copies of a snapshot. However, unlike views, which are copies of the entire volume group, clones are copies of specific volumes in the snapshot. Additionally, while snapshots and views are limited per volume group, the number of clones is only limited by the total number of volumes supported by the Silk DataPod.
There are two types of clones that can be created: thin and thick. When a clone is first created, it’s a thin clone. Like with views, this means there’s no data copied, and no additional capacity utilized until changes are made. A full clone (also called a thick clone) takes a thin clone and converts it to a standalone volume. During this conversion, data is copied in the background while still serving IO, and its association with its source snapshot is broken.
Key Features of Clones
- Higher limits: the number of volumes allowing for copies of data with minimal overhead limits the number of clones.
- Enhanced flexibility: Unlike views, clones allow for specific volumes to be extracted from a snapshot.
- Option for full data hydration: Thin clones can be converted to thick clones, which will convert the clones to standalone volumes.
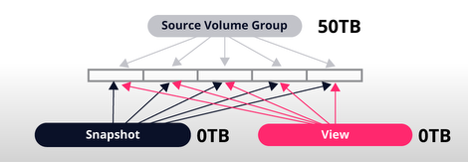
Scenario 1: Snapshot and View Created With No Changes
Initially, when a snapshot and view are created without any changes to the source volume group (VG), no additional storage capacity is used. Both the snapshot and view reference the same original data blocks as the source VG.
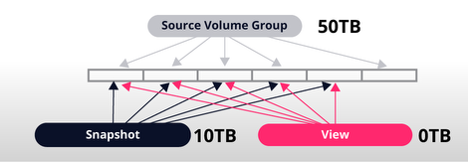
Change 1: Restoring a Table in the Source Volume Group
When changes occur, such as restoring a table in the source VG:
- The source VG itself doesn’t grow, but the Silk DataPod tracks the restore operation as a new write.
- The snapshot now consumes space, referencing the previous state. In this example, the difference between the previous state and the new restored state is 10TB.
- The view, unchanged, still points to the snapshot’s blocks and thus doesn’t consume additional storage.
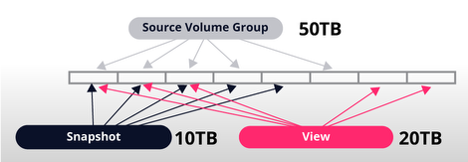
Change 2: Modifying the View
If changes are introduced directly into the view:
- The view now starts consuming space independently, as these writes are treated as new blocks of data.
- This additional usage arises because the view’s blocks now diverge from the snapshot’s original blocks. In this example, the changes to the view consume 20TB.
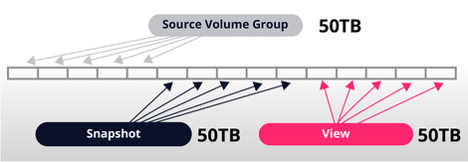
Change 3: Full Database Restore of the Original Volume Group and View
Here we’ll assume a worst-case scenario where a full restore was performed on the source volume group and on the view. During a full database restore:
- The original VG now references entirely new data blocks due to a complete
- The snapshot continues to reference the original blocks captured at the snapshot’s creation.
- The view, having gone through its own full restore process, references its new, separate blocks.
While this is an extreme example, a similar situation can occur in environments with high change rates and/or long-standing snapshots and views.
Scenario 2: Thin Clones vs Views
Aside from the differences in limits, another benefit of clones is the ability to present specific volumes from the snapshot rather than all the volumes. We commonly see 1:1 mapping between a host and a volume group. In the case of database environments, this usually means there are multiple volumes for different databases in a single volume group.
Before clones were available, if the ask was to present a copy of a specific database, the solution would have been to move those volumes into a separate volume group to then create a snapshot and view. With clones, however, we can extract the volumes associated with a specific database without having to change the underlying structure.
Full Clone Conversion
Full clones, sometimes referred to as thick clones, are an enhancement on thin clones. Any thin clone can be converted into a full clone, during which the underlying data will be fully copied over. This breaks its reliance on the underlying snapshot and allows it to exist like a normal volume.
Full clones can be particularly useful in cases where there are long-standing views. In such a scenario, it is likely that the original volume group, snapshot, and underlying view(s) are now completely different from one another, as illustrated in the “Full Database Restore of the Original Volume Group and View” scenario. If clones were to have been used instead, the full clone would allow us to break off from the original snapshot and reduce the capacity overhead.
Efficiency Considerations
The scenarios above show how capacity usage evolves dynamically. As snapshots and views diverge from the original VG due to ongoing changes, they begin consuming additional storage capacity. While the above examples are simplified, in practice, managing multiple snapshots and views further compounds this complexity.
By understanding these systems, storage administrators can manage and predict how much storage space is used. This will help them manage storage better with Silk software-defined cloud storage.
Ready to Learn More?
As we’ve illustrated, Silk’s snapshots, views, and clones optimize data storage efficiency by reducing unnecessary data duplication and leveraging pointers to existing data blocks. These built-in efficiencies can lead to significant savings of up to 40 percent or more on cloud data costs. To discover your organization’s potential savings, try Silk’s cost-savings calculator today.
Calculate Your Cost Savings
Discover your organization’s potential savings with Silk’s cost-savings calculator.
Calculate My Savings


