This article was originally posted on DBAKevlar on July 16, 2024.
There’s a large influx of PostgreSQL databases coming into the market. It only makes sense to use this robust open-source database for any new project and to migrate those which can to an open-source solution, saving thousands, if not millions of dollars in database licensing costs. Most of these deployments are as PaaS (Platform as a Service) databases with cloud vendors. To maintain the ability to scale to meet the needs of so many customers, cloud vendors, in general, limit and throttle individual resources. Logically, if you’re able to determine what individual resources will require, it’s much easier to control the demand as it increases by quantity of users globally. With this understanding, I’m less expecting of cloud vendors to handle the demands of larger, unique workloads and accept the opportunity to use PostgreSQL for smaller database workloads and new projects.
Recently I was tasked with running some benchmark tests on a flavor of PostgreSQL from Google, called AlloyDB Omni, that doesn’t just run in one cloud, but can be unchained from Google cloud and run as a docker container in ANY cloud. The cloud vendor was curious what kind of performance results I could achieve if I put Silk underneath it. As it’s PostgreSQL, HammerDB is the benchmark tool of choice and the tests provided interesting results. I believe this is just the first of many PaaS databases unchaining from its cloud master and expect to see more in the future.
Now I am a data/infra specialist, which is a strange combo – commonly you are data and analytics or infrastructure with maybe security or networking, but data/infra puts me in an odd VEN diagram of tech-
I’m a solid resource for performance testing because although I’m database, I know that infrastructure, database design, workload and resources allocated all contribute to the results in a benchmark test. If you have an optimal infrastructure setup, but the workload, database design or the resources allocated during the benchmark run via parameter settings or configurations aren’t optimal, performance results will be affected. I also know, as I tune one of the four areas, the bottleneck will move to one of the other four areas and I have to decide when the VEN diagram for my benchmark is most optimal, which I also refer to as “Benchmark Heaven.”
You’ll notice it’s much more evenly distributed than my own skillset…:)
As you perform benchmark tests, you can’t just inspect the infrastructure performance and assume you’ve covered your bases. As I just stated in my diagram, when doing database benchmark testing, you have to take the database design (configuration, code and internal object architecture), resources allocated, (memory, CPU and storage IO) and workload issued into consideration.
For the test and blog post at hand, I was performing a test on AlloyDB Omni and I wanted to identify the upper limits of IO for it on Azure with Silk. There are three HammerDB articles/documents the tests from these blogs will be focused on, please feel free to check them out if you’d like to learn more:
AlloyDB Omni Benchmarking Guide
What I Learning Benchmarking Citus and Postgres with HammerDB
Postgres Price vs. Performance Benchmarking
We’re not going to dig into all of my findings today, but this is the first part as we learn with Postgres and the art of what is possible.
Baby Steps
The idea was to perform two sets of tests, one using the recommended values for AlloyDB Omni to get a baseline for this flavor of Postgres and see what Silk could get in performance. Once that was complete, could I think supplement this testing and match the settings used in the Gigacom article to compare the performance to other flavors of Postgres that were popular in the market.
Following the AlloyDB Omni documentation for testing with HammerDB the original test would be run against native storage in Azure. AlloyDB Omni is run inside a docker container and using Azure premium SSD with the following values in my HammerDB setup.env file:
Warehouse count: 3200
User count: 256
My virtual environment in Azure was as follows:
VM: 16 vCPU, 64GB of memory and limit of 1200MBPs max for native, attached storage.
Storage: Azure Premium SSD P40, 2 TB
The first test numbers were very low, as expected and I bottomed out as soon as I hit them top capabilities of the storage, which was around 400MBPs for a 30% write/70% read configuration.
As expected, the results were pretty dismal, as premium SSD wasn’t able to offer significant IO underneath the covers.
Test I
Vuser 1:TEST RESULT : System achieved 18091 NOPM from 41662 PostgreSQL TPM
Using the same VM, I deployed a Silk configuration with 2 c.nodes, which is only limited by the network , even for a smaller VM of 16vCPU. I then moved the docker container to run from Silk instead of the Azure premium SSD. Using Silk for the storage layer means that I can continue to read as much as I want till I saturate the network and the writes are throttled often at a higher rate than the limits set for attached storage. The bottleneck will now occur when I hit that or when I hit one of vCPU or database.
Test II
Vuser 1:TEST RESULT : System achieved 465213 NOPM from 1031103 PostgreSQL TPM
The is a huge difference vs. the Azure native storage and its easy to see how Silk can increase the IO performance vs. a native solution. Upon inspecting the VM and Silk, I was aware that the bottleneck wasn’t on the VM or the storage solution, so I was now curious if I could offer some improvement at the database tier.
Move the Bottleneck off of the Database
The question now came to what parameters were there that might assist in offering better results at the database tier? As this is a benchmarking tool, I’m not able to offer much that wasn’t already done on the test for optimization and due to this, wouldn’t be optimizing any code.
The default configuration of the database running on docker was optimized for Google cloud, no infrastructure, as it needed to make sure no one became the noisy neighbor across the service. It was now time to scale our parameters at the database tier what might not be optimal now that AlloyDB Omni was running outside of Google cloud as a service and see if we could gain additional performance. What ones would I choose?
Parameter Buffet
shared_buffers = 25GB
Now this value isn’t included in the flavor of PostgreSQL that I’m working on, but I decided to test it out and yes, this change made a difference in my benchmark test by about 5%, so I set it to 25GB, even though there were mixed reviews on the benefit in blog posts, etc.
wal_buffers = 64MB
Default value for the wal_buffers is 16MB and I updated this to a more optimal value for the benchmark workload to 64MB. This is a change that has a varied degree of success in my experience, but I would recommend anyone to test it and verify if it has value for your own benchmark combination of tests.
As the next value could be a concern for a production environment and the benchmark I’m performing is not a production system with data protection concerns or a DR replica, I chose to change the synchronous commit value from on to off.
synchronous_commit = off
Your wal, (i.e. buffer values for those of us who may come from other enterprise database platforms) are extremely important to perform in memory what should be done in memory and then conserve IO for the important items that can’t be done there.
max_wal_sender = 0
I updated this from originally 50. 0 is unlimited, which means it will grow the value as required and that way is dynamic.
max_wal_size = 3000MB
The installation defaults were set to 1504MB and the recommendation is to have upwards to 30% of your host memory allocated to this value. There are some mixed information regarding to the value of changes to this parameter, so consider the size of your environment and the max value limits for this parameter.
With these changes, did I achieve better performance?
Test III
Vuser 1:TEST RESULT : System achieved 585562 NOPM from 1393581 PostgreSQL TPM
For my tests, the changes were worth the additional parameter changes.
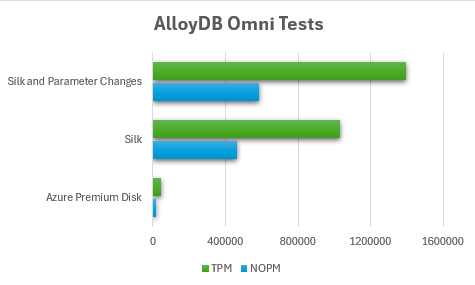
I’m now back to maxing out all of the vCPU on the VM. There’s a ton of data that I’ve collected on comparisons to other flavors of PostgreSQL vs. AlloyDB Omni with Silk, TCO value and scaling to larger VMs, but for those insights, you’ll just have to wait and see the upcoming posts from Google and Silk!



