The Growing Challenge of Data Duplication in AI and Analytics
As enterprises increasingly adopt AI-driven analytics, the demand for efficient data access continues to rise. Oracle Autonomous Data Warehouse (ADW) is a powerful platform for analytical workloads, but AI-enhanced processes—such as Agentic AI, Retrieval-Augmented Generation (RAG), and predictive modelling—place new strains on data management strategies.
A key issue in supporting these AI workloads is the need for multiple data copies, which drive up storage costs and operational complexity. Traditional approaches to data replication no longer align with the scale and agility required for modern AI applications, forcing organizations to rethink how they manage, store, and access critical business data.
This blog builds upon my previous post on AI Agents in the Oracle Analytics Ecosystem, further exploring how AI-driven workloads impact traditional data strategies and how organizations can modernize their approach.

Why AI Workloads Demand More Data
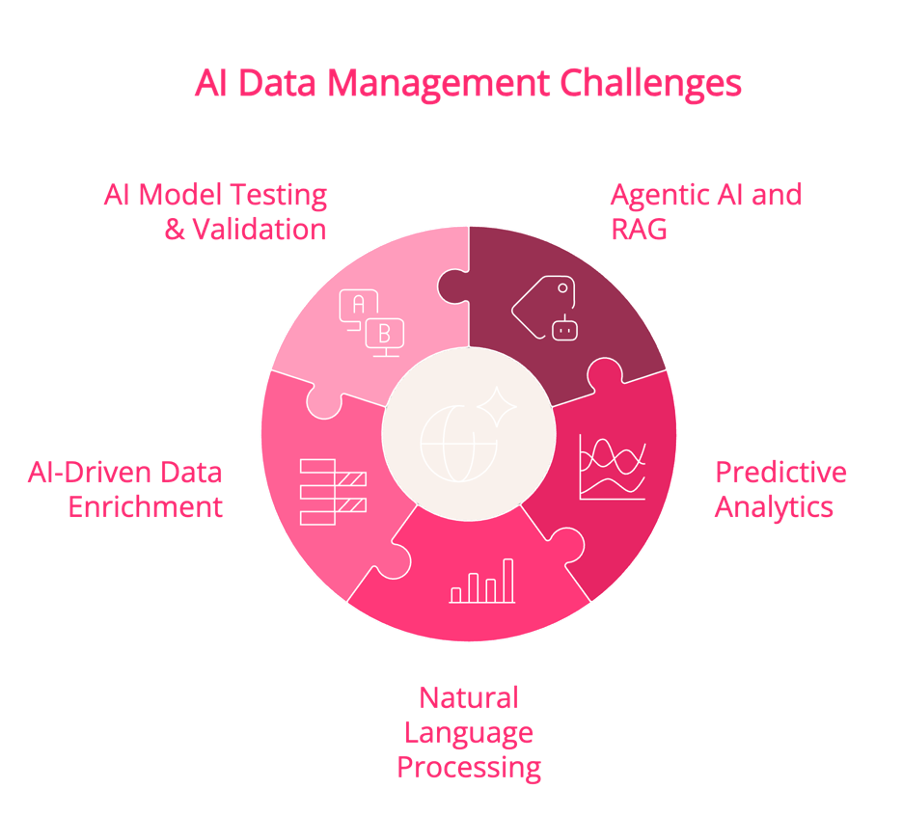
AI models, particularly those leveraging RAG, generative AI, and deep learning, require constant access to vast amounts of data. In Oracle ADW environments, these workloads often involve:
- Agentic AI and RAG: Continually retrieving and processing real-time or near-real-time data for enhanced decision-making, requiring multiple indexed views of the same dataset.
- Predictive Analytics: Running machine learning models that require extensive historical data for training and inference, often necessitating multiple snapshots of production data.
- Natural Language Processing (NLP): Extracting insights from unstructured data, requiring large-scale indexing, vector search capabilities, and duplication of processed text corpora.
- AI-Driven Data Enrichment: Merging structured and unstructured data sources to generate deeper insights, often leading to multiple temporary and persistent data copies.
- AI Model Testing and Validation: Deploying and fine-tuning AI models across different datasets requires isolated environments, each consuming additional storage resources.
IDC has extensively documented the exponential growth of data and AI investments. Recent industry reports indicate that data storage requirements for AI workloads are expanding at an unprecedented rate.
IDC’s broader research reveals several critical insights about AI’s accelerating impact on data ecosystems:
- Global Datasphere Growth: IDC forecasts the global datasphere will reach 394 zettabytes by 2028 (up from 149ZB in 2024), representing a 19.4% compound annual growth rate. While this encompasses all data, AI workloads are a primary driver: 90ZB of data will be generated by IoT devices by 2025, much of it processed by AI systems . Real-time data (crucial for AI) will grow to 30% of all data by 2025, up from 15% in 2017.
- AI-Specific Infrastructure Demands – Spending on AI-supporting technologies will reach $337B in 2025, doubling from 2024 levels, with enterprises allocating 67% of this budget to embedding AI into core operations. AI servers and related infrastructure are growing at 29-35% CAGR, outpacing general IT spending.
- Generative AI Acceleration IDC predicts Gen AI adoption will drive $1T in productivity gains by 2026, with 35% of enterprises using Gen AI for product development by 2025. This requires massive data processing: Cloud platform services supporting AI workloads are growing at >50% CAGR. AI-optimised PCs will comprise 60% of all shipments by 2027, enabling localized data processing. Enterprise AI spending doubling from $120B (2022) to $227B (2025) in the U.S. alone. Gen AI spending projected to reach $202B by 2028, representing 32% of total AI investments .
The data explosion is being fuelled by AI use cases like augmented customer service (+30% CAGR), fraud detection systems (+35.8% CAGR), and IoT analytics. IDC emphasizes that 90% of new enterprise apps will embed AI by 2026, ensuring continued exponential data growth at the intersection of AI adoption and digital transformation.

The Traditional Approach: Cloning Production Data
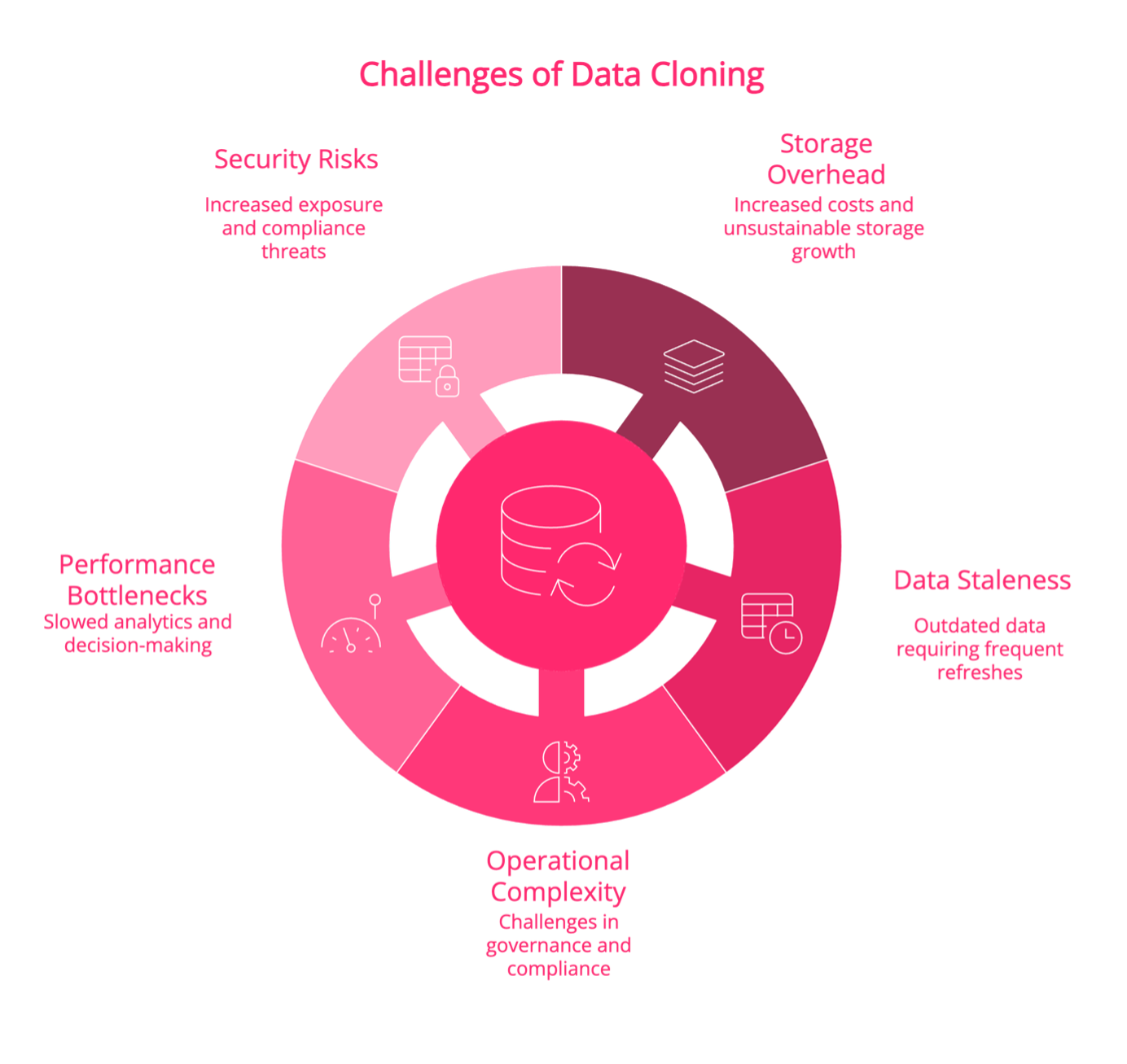
Historically, organizations have relied on full database cloning to create isolated environments for AI training, model validation, and analytics. While this approach ensures data consistency, it comes with significant drawbacks:
- Storage Overhead: Each cloned copy requires additional storage, leading to exponential growth in consumption and costs. For organizations processing terabytes or petabytes of data, this rapidly becomes unsustainable.
- Data Staleness: Cloned datasets quickly become outdated, requiring frequent refreshes that consume computing resources and delay AI-driven insights.
- Operational Complexity: Managing multiple cloned copies increases administrative overhead, creating challenges in data governance, version control, and compliance.
- Performance Bottlenecks: As AI models interact with production or cloned datasets, increasing query loads can degrade performance, slowing down analytics and decision-making.
- Security & Compliance Risks: More data copies mean more potential points of exposure, increasing the risk of non-compliance with regulations such as GDPR, CCPA, and industry-specific mandates.
Cost Implications of Traditional Data Cloning
To put this into perspective, consider a mid-sized enterprise running an Oracle ADW instance with 50TB of data. If multiple teams require their own clones for model training and testing, the storage footprint could easily reach 250TB or more. With cloud storage costs averaging $0.02 per GB per month, this could result in annual expenses exceeding $80,000—just for storage alone. Factor in compute, additional database costs and administrative overhead, and the financial impact becomes even more pronounced.
The challenge becomes particularly acute when considering the unique characteristics of AI workloads. Traditional RDBMS architectures were designed for transactional processing and structured analytical queries, but AI workflows introduce several distinct pressures:
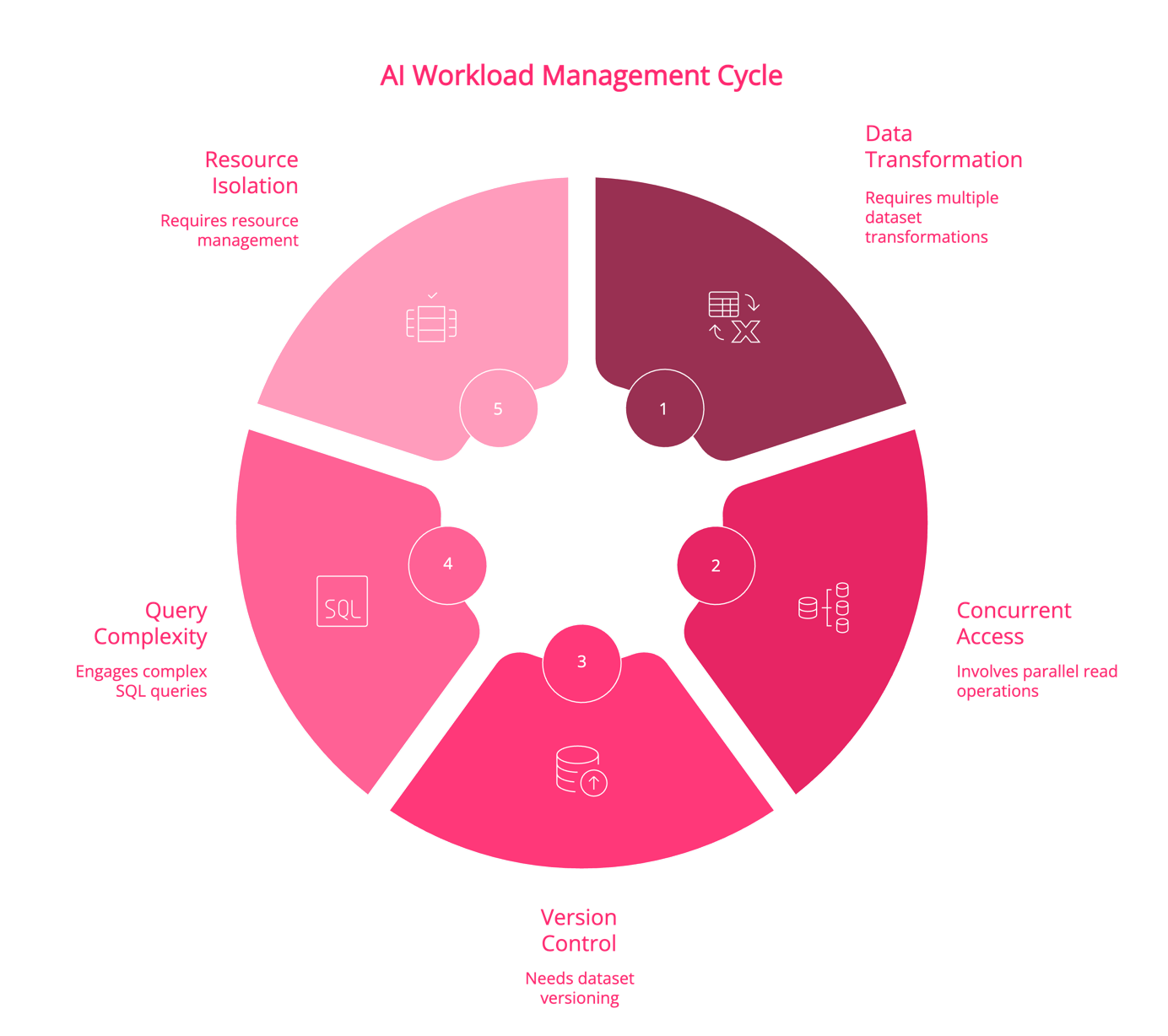
Data Transformation Requirements: Machine learning models often require multiple transformations of the same dataset for feature engineering, resulting in numerous intermediate tables and views. These transformations must be stored and versioned, further multiplying storage requirements.
Concurrent Access Patterns: AI training workflows typically involve intensive parallel read operations across large datasets, which can overwhelm traditional buffer pools and I/O subsystems designed for mixed read/write workloads. This often leads to performance degradation for other database users.
Version Control and Reproducibility: ML teams need to maintain multiple versions of datasets for experiment tracking and model reproducibility. Traditional RDBMS systems lack native support for dataset versioning, forcing teams to create full copies or implement complex versioning schemes at the application level.
Query Complexity: AI feature engineering often involves complex transformations that push the boundaries of SQL optimization. Operations like window functions, recursive CTEs, and large-scale joins can strain query optimizers designed for traditional business intelligence workloads.
Resource Isolation: When multiple data science teams share the same RDBMS instance, their resource-intensive operations can interfere with each other and with production workloads. Traditional resource governors and workload management tools may not effectively handle the bursty nature of AI workloads.
Additionally, the need for data freshness adds another layer of complexity. Teams often require recent production data for model training, leading to regular refresh cycles of these large datasets. This creates significant network traffic and puts additional strain on production systems during clone or backup operations.
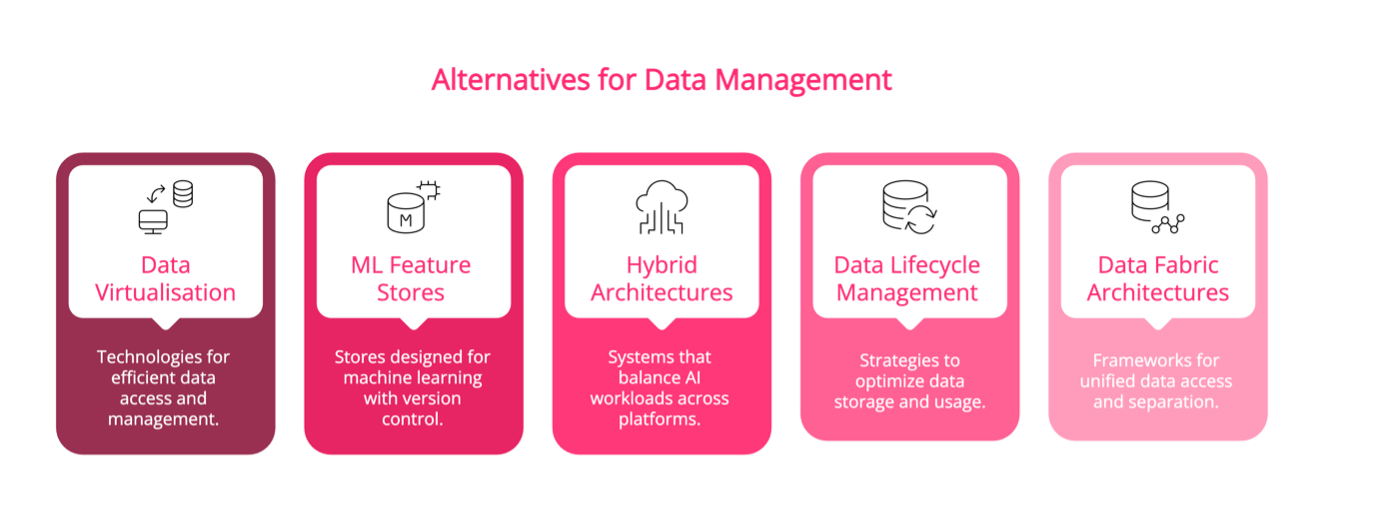
To address these challenges, organizations are increasingly exploring alternatives such as:
- Data virtualization and zero-copy cloning technologies
- Purpose-built ML feature stores with versioning capabilities
- Hybrid architectures that offload AI workloads to specialized platforms
- Automated data lifecycle management to control storage costs
- Implementation of data fabric architectures that provide unified access whilst maintaining physical separation of AI and operational workloads
The financial implications extend beyond direct storage costs. Organizations must consider:
- Additional licensing costs for database features required to support AI workflows
- Network egress charges for data movement between environments
- Increased operational complexity and associated staffing costs
- Potential performance impact on production systems
- Compliance and security overhead for managing sensitive data across multiple environments
As AI workloads continue to grow, organizations need to carefully evaluate their data architecture strategy to ensure it can scale sustainably whilst maintaining performance and cost efficiency.
To overcome these challenges, organizations need to explore advanced solutions that optimize data management while maintaining performance, scalability, and compliance.
Silk: A Smarter Approach to AI Data Management
Silk is an AI cloud storage platform that enables organizations to modernize their data strategies by tailoring to the demands of AI and analytics. Silk’s innovative technology optimizes data replication and access in cloud environments, eliminating unnecessary duplication and ensuring seamless scalability.
How Silk Works
Virtualized Data Access – Silk empowers AI workloads to access data stored in Oracle ADW and other environments without requiring full duplication. This approach reduces storage costs while maintaining high-speed access.
High-Performance Caching – Frequently accessed data is cached efficiently to ensure rapid query performance, even for the most demanding AI workloads.
Seamless Integration – Silk integrates with Oracle ADW, vector databases, and AI model pipelines, reducing the need for repeated ETL processes and simplifying data workflows.
Cost Optimization– By eliminating redundant data copies, organizations can significantly cut down on storage costs while maintaining AI performance.
Key Benefits of Silk for Oracle ADW and AI Workloads
- Storage Optimization: Reduces storage consumption by up to 80%, cutting costs while increasing efficiency.
- Real-Time Data Access: Ensures AI models always work with the most up-to-date information, reducing the lag introduced by traditional cloning processes.
- Accelerated Workflows: Removes bottlenecks associated with traditional data cloning, improving overall data pipeline performance.
- Enhanced Governance and Security: Minimize data sprawl, reducing compliance risks and administrative burden.
- Faster AI Development: Allows AI teams to test and validate models using real-time snapshots rather than outdated static clones.
Future-Proofing Oracle ADW and Oracle Analytics for AI Workloads
The rapid evolution of AI and analytics demands that organizations build future-proof architectures that can scale with new workloads. Silk Echo plays a crucial role in this by:
- Enabling AI-Ready Data Architectures: With Silk Echo, Oracle ADW can handle the increasing demands of AI-driven analytics without compromising performance or cost efficiency.
- Supporting AI Innovations: As AI models become more sophisticated, they will require dynamic and optimized access to real-time data. Silk Echo ensures that models always have the freshest data available.
- Ensuring Long-Term Cost Efficiency: By minimizing unnecessary data replication, Silk Echo provides a sustainable cost model that allows organizations to allocate resources more effectively to AI initiatives.
- Enhancing Data Virtualization Capabilities: The ability to create lightweight, instant extracts means organizations can easily integrate Oracle Analytics with broader AI ecosystems, improving analytical outcomes.
The Future of AI and Analytics in Oracle ADW
Silk’s high-performance cloud platform ensures organizations are prepared to meet the evolving demands of AI-driven analytics. By integrating seamlessly with Oracle ADW, Silk supports innovative use cases while maintaining cost efficiency, scalability, and compliance.
As AI adoption grows, organizations leveraging Silk’s capabilities can:
- Reduce the financial burden of storage-intensive AI processes.
- Ensure AI-driven applications operate with real-time, accurate data.
- Improve compliance and governance without slowing down innovation.
- Scale AI and analytics workloads without excessive data duplication.
Are You Ready to Optimize Your AI-Driven Analytics in Oracle ADW?
By adopting next-generation storage solutions like Silk’s next-generation storage solution, organizations can unlock the full potential of AI while keeping costs under control. Investing in efficient data management strategies today will ensure businesses remain competitive in the AI-driven future.
Ready to Boost Your AI Innovation?
Discover how leading organizations like PTC, Sentara Health, and Franciscan Healthcare are using Silk and Microsoft to forward their AI business goals.
Let's See What They're Doing!