Data is at the core of every business application. Because of this, database performance optimization is crucial for you and your team. Optimization begins with setting your primary goals (e.g. 95th percentile <10ms query response) and then looking at what tuning can impact that goal or KPI. Cloud database performance is a set of trade-offs between performance, efficiency, and costs.
What are the trade-offs with databases when optimizing for performance? As data volumes continue to grow exponentially, ensuring optimal response times and database performance becomes an essential task for database administrators (DBAs). Optimizing them is not a one-time task. It’s a continuous journey through a maze of configurations, trade-offs, and ever-evolving challenges.
This technical blog aims to equip you with:
- Valuable insights and techniques to fine-tune database configurations
- Indexing strategies to maximize impact
- How to utilize snapshots to optimize database performance
DBAs must understand the significance of performance tuning in databases and what limitations you may run into with your database platform choice. While public cloud environments offer scalability and flexibility, it’s not without complexity and challenges that require meticulous attention.
Cloud Options When Databases Need More Than PaaS
In the ever-evolving world of cloud computing, Infrastructure as a Service (IaaS) offerings from giants like Azure, Google Cloud and others have become central in hosting powerhouse relational databases such as Oracle, SQL Server, and PostgreSQL. Transitioning these complex database systems to the cloud isn’t just about migration; it’s about fully optimizing them to leverage the vast capabilities that cloud platforms provide. As organizations embark on their cloud journey, ensuring peak performance, security, and cost-efficiency becomes paramount. This article delves into the nuances of using IaaS for these prominent databases and underscores the significance of a comprehensive optimization strategy to extract maximum value from cloud infrastructure.
Keeping these considerations in mind, let’s explore the key optimization techniques for IaaS databases that empower DBAs to strike the right balance between price performance and efficiency.
Tuning Techniques for Data Queries
One of the critical factors in a database running on IaaS around performance is the efficient execution of data queries. Understanding how to analyze query execution plans helps identify application performance bottlenecks, paving the way for improved data retrieval and filtering techniques. Optimizing databases is a complex and constantly evolving task.
Analyzing Query Execution Plans for Performance Bottlenecks
The first step in optimizing data queries is to analyze the query execution plans. Query execution plans provide insights into how the database engine processes queries, indicating potential bottlenecks and areas for improvement.
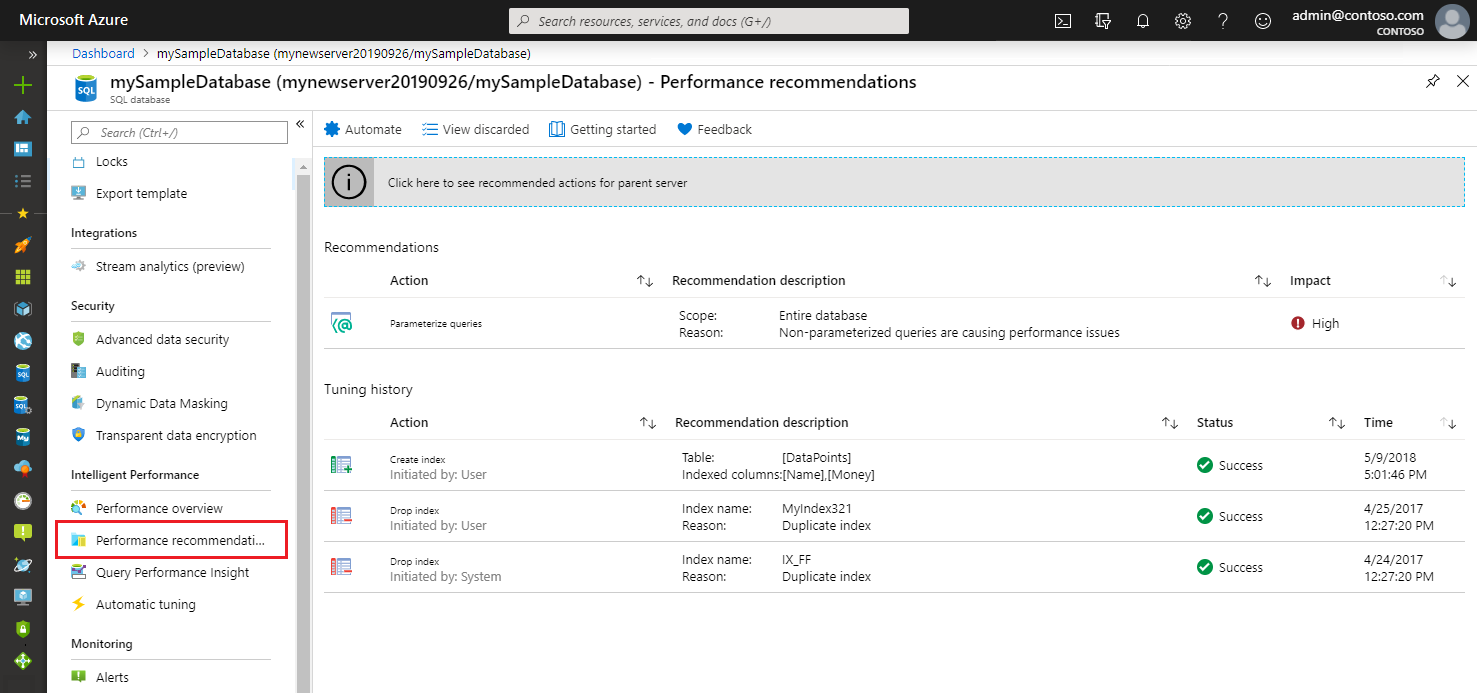
Modern database platforms offer tools for visualizing query execution plans, making it easier for DBAs to identify inefficiencies. For example, Microsoft SQL Server provides the Query Store, while Oracle has an extensive list of utilities and tools as part of the Automatic Workload Repository (AWR). Despite the advanced tools, the task remains complex and demands constant attention and adaptation, as well as deep understanding of database platform performance.
Suppose a web application frequently executes a query to retrieve customer orders based on their order status. Upon analyzing the query execution plan, the DBA discovers that the database performs a full table scan on the “orders” table, even though it has an index on the “order_status” column. This indicates an application performance bottleneck, as the database scans the entire table for each query, leading to slower retrieval times.
To address this issue, the DBA can rewrite the query to utilize the existing index effectively or create a covering index that includes all the required columns for the query. This simple optimization can significantly reduce query execution time and improve overall database performance.
Optimizing Data Retrieval and Filtering Techniques
Efficient data retrieval is essential for achieving high-performance databases running on IaaS. DBAs can optimize data retrieval by carefully selecting the columns needed for the query, thereby reducing data transfer overhead.
For example, an e-commerce application that displays product information to users could retrieve only the product name, price, and availability attributes, instead of all product attributes. This would reduce the amount of data that needs to be transferred from the database to the application, resulting in improved performance.
Filtering techniques are a way to reduce the amount of data that needs to be processed by a query. They work by identifying the rows of data that meet certain criteria and then only retrieving those rows.
Several different filtering techniques can be used, such as
- Using indexes: Indexes are a special data structure that can be used to speed up queries by storing information about the data in the database. When a query uses an index, the database can quickly find the rows of data that match the query criteria.
- Using filters: Filters are a way to specify the criteria that rows of data must meet to be included in the results of a query. Filters can be used to specify values for specific columns, or they can be used to specify more complex criteria, such as rows that were updated within a certain period.
- Using database-specific optimizations: IaaS databases often offer a variety of optimizations that can be used to improve the performance of queries. These optimizations can include things like query caching, which stores the results of frequently executed queries in memory for faster retrieval.
Using parameterized queries is another technique to improve data retrieval efficiency and prevent SQL injection vulnerabilities. Parameterized queries allow the database engine to reuse query execution plans, resulting in better application performance for repeated queries with different parameter values.
By using filtering techniques, DBAs can improve the performance of queries by reducing the amount of data that needs to be processed. This can lead to significant performance improvements, especially for queries that involve large amounts of data.
Techniques for Leveraging Caching and Query Result Optimization
SQL Server, Microsoft’s flagship relational database management system, boasts a robust memory cache feature that plays a pivotal role in optimizing database performance. This caching mechanism primarily utilizes the buffer cache, a memory pool into which data pages are read. By storing frequently accessed data in memory, SQL Server can swiftly serve repeated requests, vastly reducing the need to continuously fetch data from disk storage, which is considerably slower in comparison.
The performance benefits of utilizing SQL Server’s memory cache are manifold. Firstly, it leads to a significant reduction in I/O operations, as many read requests are satisfied directly from the buffer cache. This not only accelerates data retrieval times but also minimizes wear on physical storage devices. Additionally, by reducing disk I/O, the system can allocate more resources to other critical operations, thereby ensuring smoother overall performance. In an era where speed and responsiveness are paramount, effectively leveraging the memory cache feature can be a game-changer for businesses relying on SQL Server for their data management needs.
DBAs can utilize query result optimization techniques to further enhance application performance. Materialized views or summary tables are structures that store pre-computed results for specific queries. These structures are particularly useful for complex aggregations or reports with intensive calculations. You should carefully consider trade-offs with these approaches.
Query result performance can be challenging to find consistency with. Inefficiencies may be happening at many layers from query code down to the memory and storage performance of the underlying hardware. It’s important to pair resource monitoring with application performance to find where optimization opportunities are available.
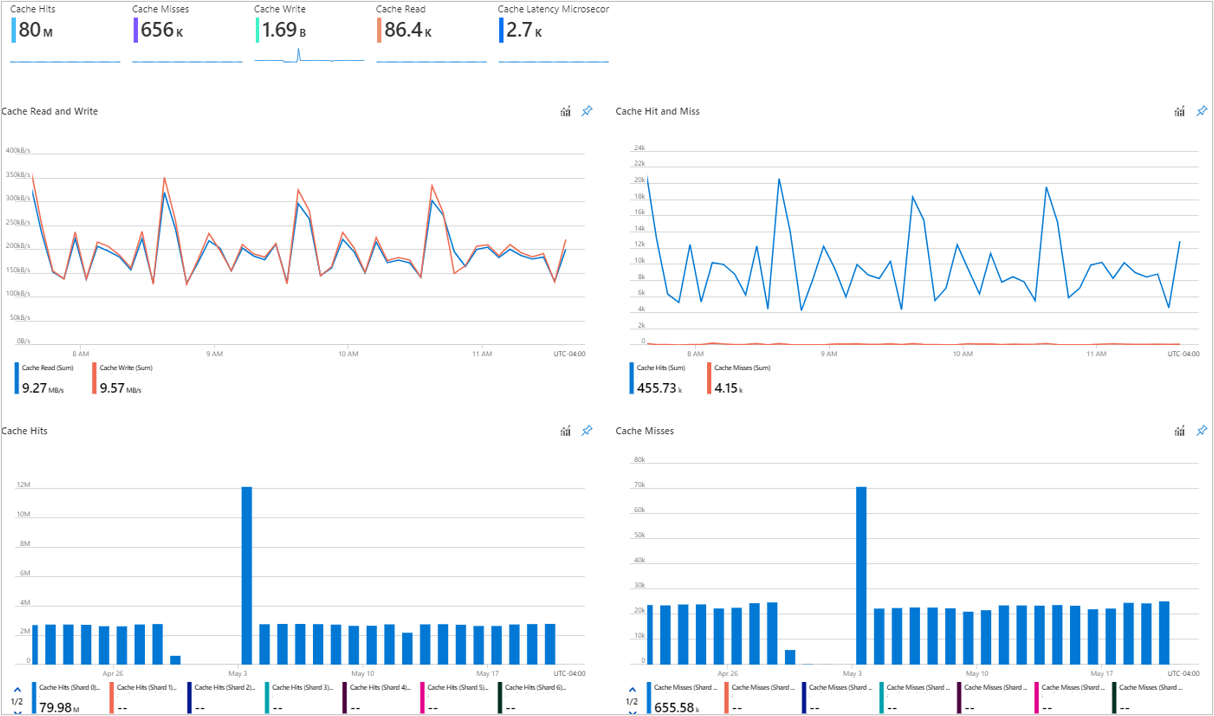
For example, with Materialized views, you will use more DB space which means higher cost but high-frequency queries can be completed quickly which could yield a business benefit to the application. On the other hand, if a precomputed view will be updated frequently but queried rarely, the costs of pre-computation and storage might not be worthwhile.
Tuning data queries is a critical aspect of achieving optimal database performance. By carefully analyzing query execution plans, optimizing data retrieval and filtering techniques, and leveraging caching and query result optimization, DBAs can unlock the full potential of their databases, enhancing performance, speed, and responsiveness.
Indexing Tips for Performance Improvement
A proper understanding of and the effective implementation of indexing strategies is crucial for optimizing database performance and resolving application performance issues.
Understanding the Significance of Appropriate Indexing in Database Performance
Indexes are data structures that allow the database engine to quickly locate relevant data, reducing the time required for data retrieval. However, improper or excessive indexing can lead to increased storage requirements and maintenance overhead.
DBAs must carefully choose the columns to be indexed, focusing on those frequently used in queries. In addition, they should consider the cardinality of the indexed columns to ensure that the index effectively narrows down the search space.
As a simple example, a cloud-based e-commerce application may have a large product catalog. By indexing the “product_category” column, the database engine can efficiently retrieve products belonging to a specific category without scanning the entire table.
Indexing Strategies for Read-Intensive versus Write-Intensive Workloads
Your indexing strategy should align with the specific workload characteristics. For read-intensive workloads, the emphasis should be on creating indexes that cover commonly used filter conditions and sorting requirements. Additionally, consider using clustered indexing, which organizes data physically based on the index, leading to faster retrieval times.
In contrast, write-intensive workloads may benefit from minimizing indexes to reduce overhead during data modification operations. Every index imposes additional overhead during inserts, updates, and deletes, as the database engine must maintain the index structure. Be careful of overusing indexes which can lead to other performance issues and unnecessary duplication of data without any performance gain.
Suppose an online gaming application stores user-generated content in a database. To enhance retrieval speed, the DBA can create indexes on attributes such as “creation_date” or “popularity.” However, for frequent updates to user-generated content, the DBA might reconsider indexing certain columns that do not heavily impact query performance.
Best Practices for Indexing in Database Environments in the Cloud
In database environments, where scalability and high availability are crucial, following indexing best practices is essential.
- Partitioning Indexes: They can improve query parallelism and reduce contention in distributed databases. Partitioning divides a large index into smaller, manageable partitions based on specific criteria, such as date ranges or geographical regions.
- Monitoring Indexes: DBAs should regularly monitor index usage and performance to identify opportunities for optimization. Many databases offer monitoring and performance analysis tools that can assist in this task.
Moreover, DBAs should leverage database-specific indexing features to further enhance performance and storage efficiency. For instance, some databases support covering indexes, where the index itself contains all the necessary data for a query, eliminating the need to access the main table.
Using Specialized Storage Virtualization to Achieve Better Performance
Optimizing SQL Server performance on Azure IaaS is a critical need for many businesses, especially when modifications to existing code or database design aren’t feasible. In such scenarios, the infrastructure becomes the focal point of performance enhancements, and integrating third-party network-attached storage solutions, like Silk, can make a significant difference.
Silk, specifically designed for cloud environments like Azure, brings a range of features that cater to high-demand database workloads. With its ability to deliver high IO throughput and low-latency data access, Silk can substantially boost SQL Server performance in Azure IaaS. Moreover, its scalability ensures that as database demands grow, the storage can effortlessly scale to meet those needs without causing disruptions. The resiliency provided by such solutions ensures that data remains accessible and safe, even in unforeseen circumstances. In essence, by leveraging third-party network-attached storage solutions like Silk, businesses can ensure that their SQL Server instances on Azure IaaS deliver peak performance, regardless of the constraints in code or design optimizations.
Introducing Data Reuse with Snapshots
Leveraging volume snapshots and thin provisioning for data reuse is a powerful strategy for achieving high-performance data access without impacting the live database or increasing cloud costs through storage allocation increase. Efficient snapshot management requires a careful understanding of snapshot lifecycles and their impact on performance and storage utilization, so additionally, know that volume snapshots and thin provisioning an enterprise-level solution like Silk may not be the same as another
Leveraging the Benefits of Data Reuse Without Impacting the Live Database
Data reuse through thin-provisioned snapshots is a powerful technique to achieve high-performance data access without affecting the live database. Silk thin-provisioned snapshots provide a read/write copy of the data at a specific point in time, enabling users to query historical data without disrupting ongoing operations.
Snapshots can be particularly beneficial for reporting and analytics workloads, which often require access to historical data. Instead of querying the live database, which may be experiencing heavy traffic from operational tasks, users can query the snapshot, ensuring a smooth user experience without impacting the database performance.
Techniques for Creating Efficient Snapshots and Utilizing Them for High-Performance Data Access
Creating efficient snapshots involves careful consideration of the data to be included and the frequency of snapshot creation. One approach is to use incremental snapshots, which capture only the changes since the last snapshot was taken. This reduces storage costs and ensures that the snapshot contains the most recent data.
Silk’s volume snapshot feature provides a robust application and command line interface to simplify the process of creating and managing snapshots. Once snapshots are created, DBAs can use them to serve read-intensive workloads, such as reporting and analytics, without impacting the live database. This separation of read and write workloads enhances overall performance and responsiveness.
Thin provisioned snapshots can also lessen the development and testing cycle with read/write clones, offering quick access to production copies, which can be redeployed at intervals during the development or testing process when failures occur when snapshots are taken at intervals.
Conclusion
Achieving database performance is a multifaceted endeavor that requires the skillful application of various tuning techniques. Throughout this article, we explored some of the key strategies to unlock the potential of database performance, empowering DBAs with valuable insights and tips.
Recapping the key takeaways:
- Tuning Techniques that Help Optimize Data Queries: Analyzing query execution plans is the first step in identifying performance bottlenecks and areas for improvement. Most database platforms offer visualization tools that aid DBAs in gaining valuable insights into query processing. By optimizing data retrieval and filtering techniques, DBAs can minimize data transfer overhead and improve query execution times. Leveraging parameterized queries and efficient caching further enhances data retrieval performance.
- Indexing Tips for Use-Cases that Can Alleviate Database Performance Issues: Appropriate indexing plays a pivotal role in improving database performance. DBAs must carefully select columns for indexing and strike a balance between performance gains and storage considerations. For read-intensive workloads, focus on creating indexes that cover commonly used filter conditions. In contrast, for write-intensive workloads, consider minimizing indexes to reduce overhead during data modification. Employing best practices for indexing in database environments ensures optimal performance.
- Introducing Data Reuse with Snapshots as a Way to Get High-Performance: By enabling access to data without impacting the live database, snapshots offer an invaluable means of data reuse. By creating efficient snapshots and employing them for read-intensive workloads, such as reporting and analytics, DBAs can significantly enhance database speed and responsiveness..
- Empowering DBAs with Optimization Tips for Unlocking Database Performance: DBAs play a pivotal role in steering databases towards peak performance. At the same time, the need to optimize is continuous and complex. Your DBA needs to be focused on data quality and integrity which may also impact application health.
- Achieving Price Performance: DBAs should also be mindful of the price performance of their database deployments. This means finding the right balance between performance and cost. Several factors can affect price performance, such as the database platform, the amount of data stored, and the workload mix.
- Incorporate Enhanced Storage Solutions: When code and traditional optimization solutions aren’t available, big performance gains can be achieved with network-attached storage virtualization solutions such as Silk.
DBAs can use a variety of techniques to improve the price performance of their database deployments. These techniques include:
- Optimizing queries: By optimizing queries, DBAs can reduce the amount of resources that are required to process them. This can lead to lower costs, as well as improved performance.
- Scaling up or down: DBAs can scale their database infrastructure up or down to match the workload. This can help to optimize performance during heavy workload periods.
Performance optimization is an ongoing process that demands vigilance and adaptability. As application usage evolves and data volumes grow, DBAs must consistently monitor, analyze, and fine-tune databases to cater to ever-changing demands.
By implementing the optimization tips and techniques shared in this article, DBAs can unlock the full potential of their databases, enhancing performance, speed, and responsiveness. Moreover, the ability to optimize data queries, employ appropriate indexing strategies, and utilize data reuse with snapshots will empower DBAs to drive their organizations towards a high-performance data infrastructure, poised for success in today’s dynamic digital landscape.
Thinking about performance as you migrate from on-prem to SaaS?
Check out the whitepaper: Building and Optimizing High-Performance SaaS Applications.
Let's Go!

